
Terraform for Network Engineers: Part Two
Simplify setup, unify configs, track changes, and automate cleanup for seamless infrastructure management.


Before diving in, if you haven’t read the first part of this series, I highly recommend starting there. In the introductory post, we covered the basics of Terraform and explored how network engineers can leverage it.
In part two, we will:
- Explore the provider documentation for Panorama.
- Set up our project and create some resources and go through the Terraform workflow.
- Review the state file.
- Reflect on our achievements so far: Have we made our lives easier?
Provider Documentation
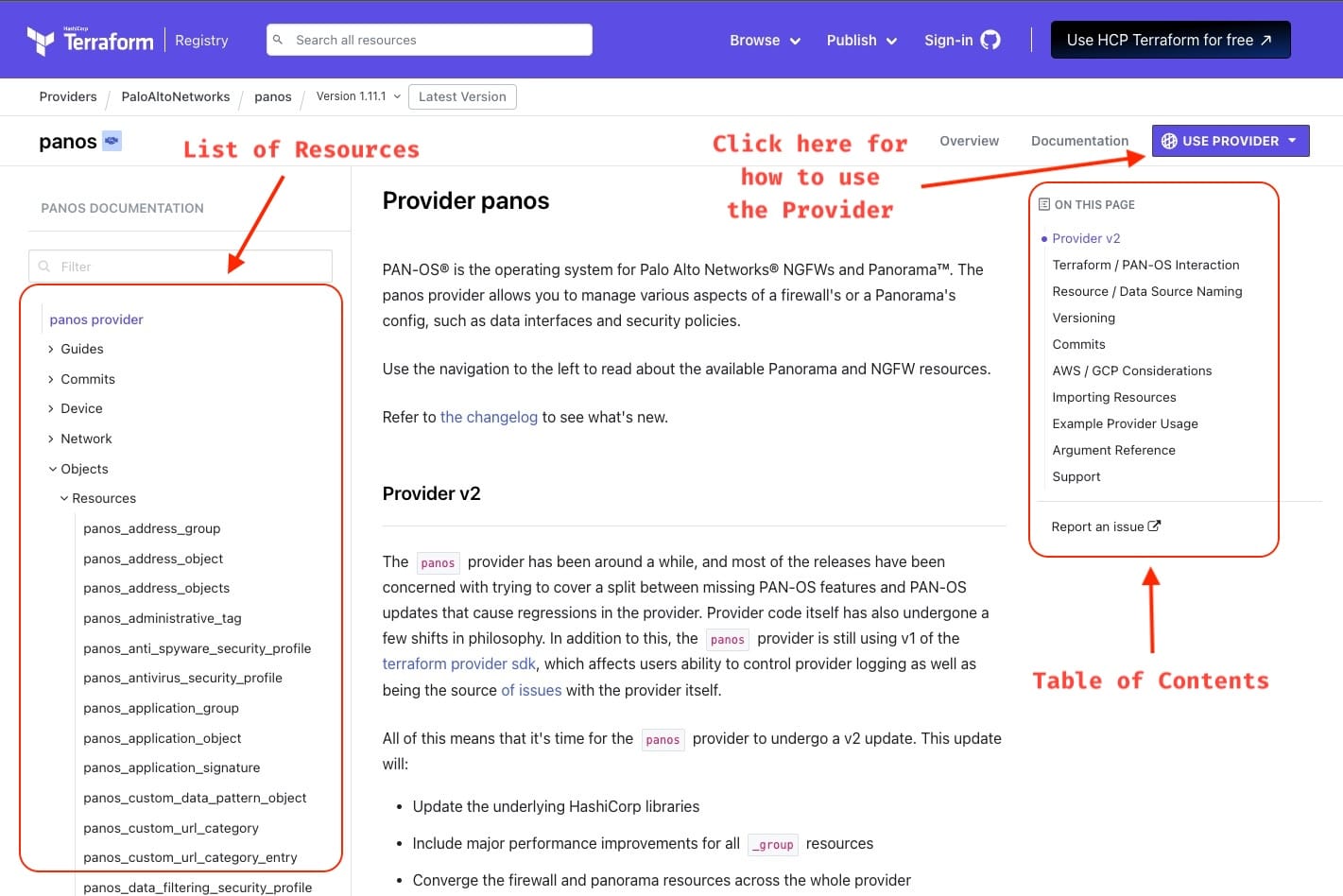
All Terraform providers have their documentation available on the Terraform website, following a similar structure.The Panorama provider documentation can be found here.
Here are a couple of screenshots highlighting the key sections of the Panorama provider documentation.
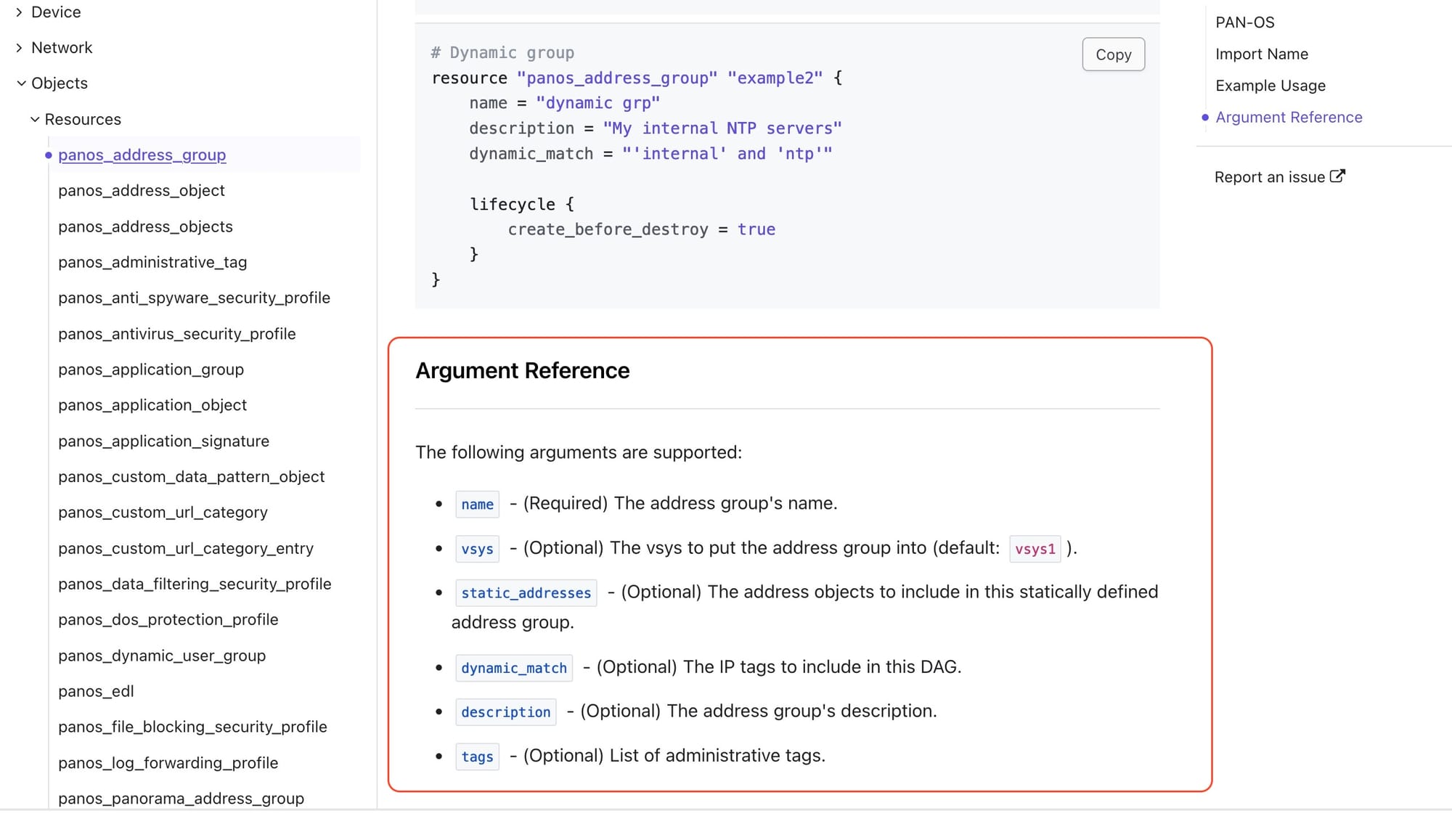
If you drill down into a Resource, you can find how the configuration block would look and what are the arguments you can pass to it.
Project Setup and Workflow
We'll set up all the files and folders needed to create resources on Panorama using Terraform. I prefer to keep my Terraform projects organized. Below is the structure I typically follow for my projects.
mkdir tf-neteng
cd tf-neteng
touch providers.tf
touch .env
touch main.tfCommands to Generate folder structure
In our project setup:
- .env: This file will store the credentials needed to authenticate with Panorama.
- providers.tf: This file will house the provider configuration for Panorama.
- main.tf: This file will contain the Terraform code defining the resources to create on Panorama.
Env File
The .env file will contain the credentials required to authenticate with Panorama. We are going to source this file in our terminal session to set the environment variables.
export PANOS_HOSTNAME="panorama.local"
export PANOS_USERNAME="yourusername"
export PANOS_PASSWORD="mysupercomplexpassword"
export VERIFY_CERTIFICATE=false
.env file
Provider File
Let's add the provider configuration to the providers.tf file.
# Define what provider we are going to use and the version number
terraform {
required_providers {
panos = {
source = "PaloAltoNetworks/panos"
version = "1.11.1"
}
}
}Providers file
Main File
The main.tf file will contain the resources we want to create on Panorama. In this example, we will create simple network object on Panorama.
resource "panos_address_object" "ao1" {
name = "ntp1"
value = "10.0.0.1"
}Main file
Terraform Workflow
Referencing back to the workflow we discussed in the first part, we will init our project, plan the changes,apply the changes and destroy the resources.
To initialize the project, we will run terraform init command in our project folder. This will download the provider plugin and initialize the project. You will notice a new folder .terraform created in the project folder. This folder contains the provider plugins. A new .terraform.lock.hcl file is also created that records the provider selections made by Terraform.

terraform initTo plan the changes, we will run terraform plan command in our project folder. This will show us the changes Terraform is going to make on Panorama.

terraform planThe plan shows us the resources that is going to be created, changed and destroyed. (Beautiful, we love to see the plan!). In this case, it is creating one network object on Panorama in the shared device group.
To apply the changes, we will run terraform apply command in our project folder. This will create the resources on Panorama. It will prompt us to confirm the changes before applying them. (only yes will be accepted to approve). we can use --auto-approve flag to automatically approve the changes.

terraform applyAt this stage, we have created a network object on Panorama using Terraform. We can verify the object on Panorama GUI or CLI.

In addition to creating the resource on Panorama, Terraform has also created a terraform.tfstate and terraform.tfstate.backup file in the project folder. This file contains the state of the resources created by Terraform. We'll discuss the state file a bit later in this post.

Now, lets fast forward a bit and look at how a main.tf file would look if we were to create a more complex configuration. We will create a couple of objects and a security policy on Panorama.
Read the inline comments to understand what each resource is doing.
# Creates an address group ntp1 on panorama
resource "panos_address_object" "ao1" {
name = "ntp1"
value = "10.0.0.1"
}
# Creates an address group ntp2 on panorama
resource "panos_address_object" "ao2" {
name = "ntp2"
value = "10.0.0.2"
}
# Creates a security policy on panorama that allows DNS traffic from Inside to DMZ
# for destination address, we are using the address objects created above and
# we are referencing them using the terraform interpolation syntax
# panos_address-object ==> resource type
# ao1 ==> resource name
# name ==> attribute name
resource "panos_security_policy" "rule1" {
device_group = "DEMO"
rule {
name = "DNS Policy"
source_zones = ["Inside"]
source_addresses = ["any"]
source_users = ["any"]
destination_zones = ["DMZ"]
destination_addresses = [panos_address_object.ao1.name, panos_address_object.ao2.name]
applications = ["dns"]
services = ["application-default"]
categories = ["any"]
action = "allow"
}
}More complex main.tf
Let us run terraform plan and terraform apply to view the plan and create the resource on Panorama.

terraform planNow lets apply it with auto-approve.

terraform applyIf you look at the plan and apply outputs closely, you will see that Terraform generated the plan for just two resources - panos_address_object.ao2 and panos_security_policy.rule1. This is because panos_address_object.ao1 was already created in the previous step. Terraform tracks the resources it has created in a file called terraform.tfstate. This enables Terraform to know the state of the resources and only create the resources that are not present in the state file.
State File
The terraform.tfstate file is a json file that contains the state of the resources created by Terraform. It contains the configuration of the resources and the metadata required to manage the resources. The state file is used by Terraform to determine the changes that need to be made to the resources at each plan and apply stages. It is also used to track the dependencies between resources.
If you look at our state file, you will see the configuration of the resources we created.
{
"version": 4,
"terraform_version": "1.9.0",
"serial": 4,
"lineage": "71284a8c-4f8b-5370-f898-f44f6e30607b",
"outputs": {},
"resources": [
{
"mode": "managed",
"type": "panos_address_object",
"name": "ao1",
"provider": "provider[\"registry.terraform.io/paloaltonetworks/panos\"]",
"instances": [
{
"schema_version": 1,
"attributes": {
"description": "",
"device_group": "shared",
"id": "shared:ntp1",
"name": "ntp1",
"tags": [],
"type": "ip-netmask",
"value": "10.0.0.1",
"vsys": "vsys1"
},
"sensitive_attributes": [],
"private": "<redacted>"
}
]
},
{
"mode": "managed",
"type": "panos_address_object",
"name": "ao2",
"provider": "provider[\"registry.terraform.io/paloaltonetworks/panos\"]",
"instances": [
{
"schema_version": 1,
"attributes": {
"description": "",
"device_group": "shared",
"id": "shared:ntp2",
"name": "ntp2",
"tags": null,
"type": "ip-netmask",
"value": "10.0.0.2",
"vsys": "vsys1"
},
"sensitive_attributes": [],
"private": "<redacted>"
}
]
},
{
"mode": "managed",
"type": "panos_security_policy",
"name": "rule1",
"provider": "provider[\"registry.terraform.io/paloaltonetworks/panos\"]",
"instances": [
{
"schema_version": 1,
"attributes": {
"device_group": "DEMO",
"id": "DEMO:pre-rulebase:vsys1",
"rule": [
{
"action": "allow",
"applications": [
"dns"
],
"audit_comment": "",
"categories": [
"any"
],
"data_filtering": "",
"description": "",
"destination_addresses": [
"ntp1",
"ntp2"
],
"destination_devices": null,
"destination_zones": [
"DMZ"
],
"disable_server_response_inspection": false,
"disabled": false,
"file_blocking": "",
"group": "",
"group_tag": "",
"hip_profiles": null,
"icmp_unreachable": false,
"log_end": true,
"log_setting": "",
"log_start": false,
"name": "DNS Policy",
"negate_destination": false,
"negate_source": false,
"negate_target": false,
"schedule": "",
"services": [
"application-default"
],
"source_addresses": [
"any"
],
"source_devices": null,
"source_users": [
"any"
],
"source_zones": [
"Inside"
],
"spyware": "",
"tags": null,
"target": [],
"type": "universal",
"url_filtering": "",
"uuid": "1932cfd4-9dea-489a-8b48-81acd269acb2",
"virus": "",
"vulnerability": "",
"wildfire_analysis": ""
}
],
"rulebase": "pre-rulebase",
"timeouts": null,
"vsys": "vsys1"
},
"sensitive_attributes": [],
"private": "<redacted>",
"dependencies": [
"panos_address_object.ao1",
"panos_address_object.ao2"
]
}
]
}
],
"check_results": null
}Terraform State file
The terraform.tfstate.backup file is a backup of the terraform.tfstate file before the last operation. It can be used to restore the state file in case of corruption.
If you look at our state file backup, it contains just one resource which was the state file before out last operation of adding another address object and a security policy.
{
"version": 4,
"terraform_version": "1.9.0",
"serial": 1,
"lineage": "71284a8c-4f8b-5370-f898-f44f6e30607b",
"outputs": {},
"resources": [
{
"mode": "managed",
"type": "panos_address_object",
"name": "ao1",
"provider": "provider[\"registry.terraform.io/paloaltonetworks/panos\"]",
"instances": [
{
"schema_version": 1,
"attributes": {
"description": "",
"device_group": "shared",
"id": "shared:ntp1",
"name": "ntp1",
"tags": null,
"type": "ip-netmask",
"value": "10.0.0.1",
"vsys": "vsys1"
},
"sensitive_attributes": [],
"private": "<redacted>=="
}
]
}
],
"check_results": null
}Terraform state backup file
terraform.tfstate file and terraform.tfstate.backup should not be modified manually. It is managed by Terraform and should be treated as a black box.Before we move on, lets destroy the resources we created using Terraform. We will run terraform destroy command in our project folder. This will delete the resources Terraform created on Panorama. It knows what to delete from the information in the state file.

terraform destroyReflecting and Planning Ahead
Wow, we've covered a lot of ground! Let's take a moment to recap our achievements.
- Automation with Terraform: We created a network object and a security policy on Panorama using Terraform.
- Terraform in Action: We witnessed how Terraform generates a plan and applied changes to resources. (That plan output is quite satisfying, right?)
- Terraform State: We explored how Terraform tracks the state of resources with the state file.
But have we truly simplified our tasks?

Let's break down why:
- Setup Complexity: Are we really expecting network engineers to set up a Terraform project and write HCL code for creating resources?
- Documentation Dive: Are network engineers supposed to dig into Terraform provider documentation to configure their desired resources?
- State File Management: What do we do with the state file? How do we manage it and share it with the team? What if it gets corrupted?
Stay tuned for the next part of this series, where we'll address these questions and explore solutions.
Thought Provokers
Imagine if we somehow addressed the above challenges and simplified the setup, execution and management. What would we achieve?
What if we had one Terraform project stored in a version control system (Git), per service/application and configured our firewall policies. What would that mean?
- A documented source of truth for all the configurations applied to our firewall infrastructure for that service/application.
- A complete history of all changes made to the firewall infrastructure for each service/application over time.
- If we included our load balancer, DNS, and VM configurations in the same Terraform project. We'd have a unified source of truth for our entire infrastructure for that service/application.
- The state file is JSON, right? What if we could store it in a database and query it anytime to get the configuration of our infrastructure? We'd end up with a self-documented application infrastructure.
- If a service/application is being decommissioned, We could just run
terraform destroy, and the configuration would be removed from the firewall, load balancers and DNS. No more manual cleanup required.

I'll leave you with these thought-provoking ideas. Until next time!
All the code you saw in this post can be found in the below repository.



